Paper reading: Language Models can Solve Computer Tasks
UCI/CMU, NIPS 2023
Motivation
Previous agents need a large amount of expert demonstration and task specific reward functions to be able to solve unseen tasks.
An LLM can execute computer tasks guided by NL prompts.
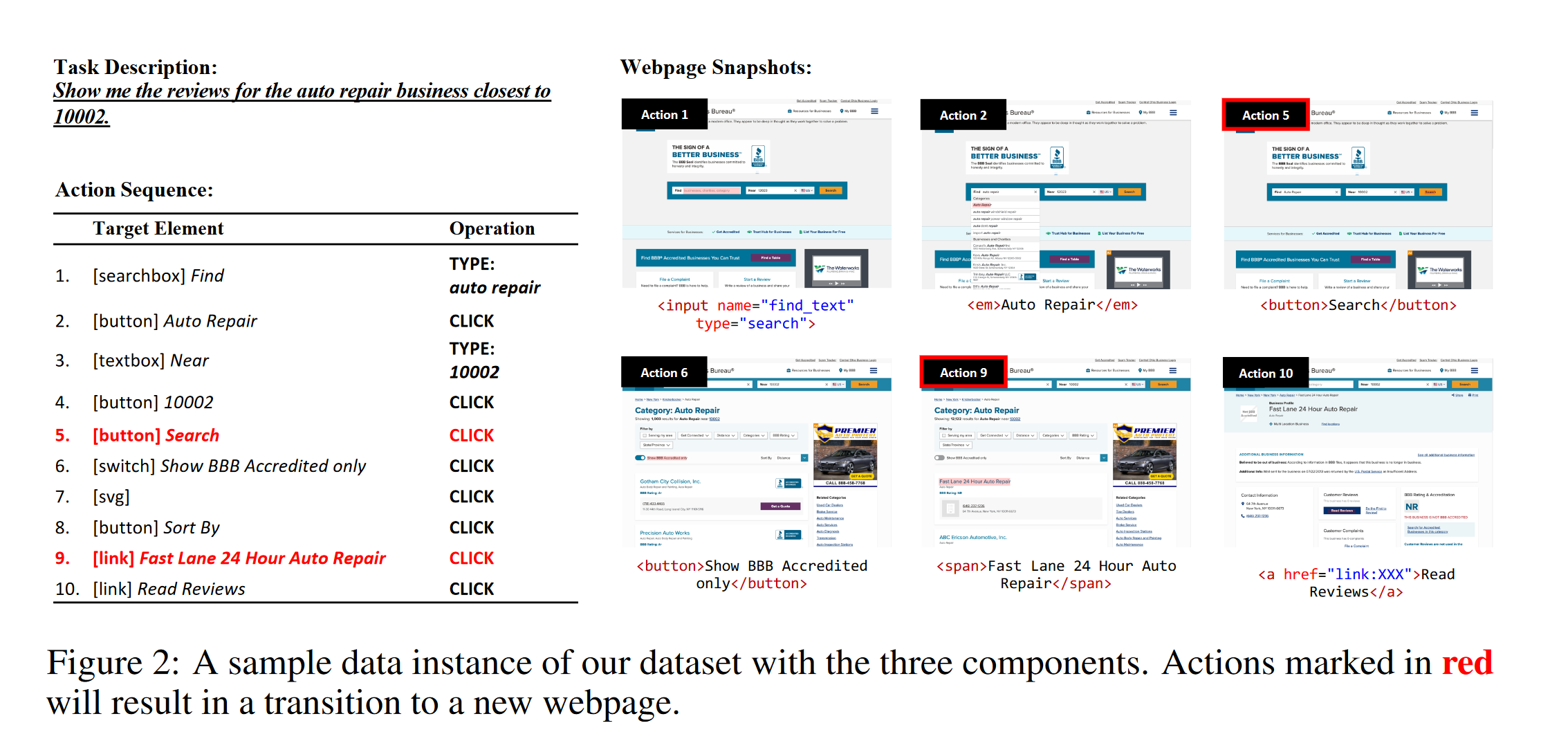
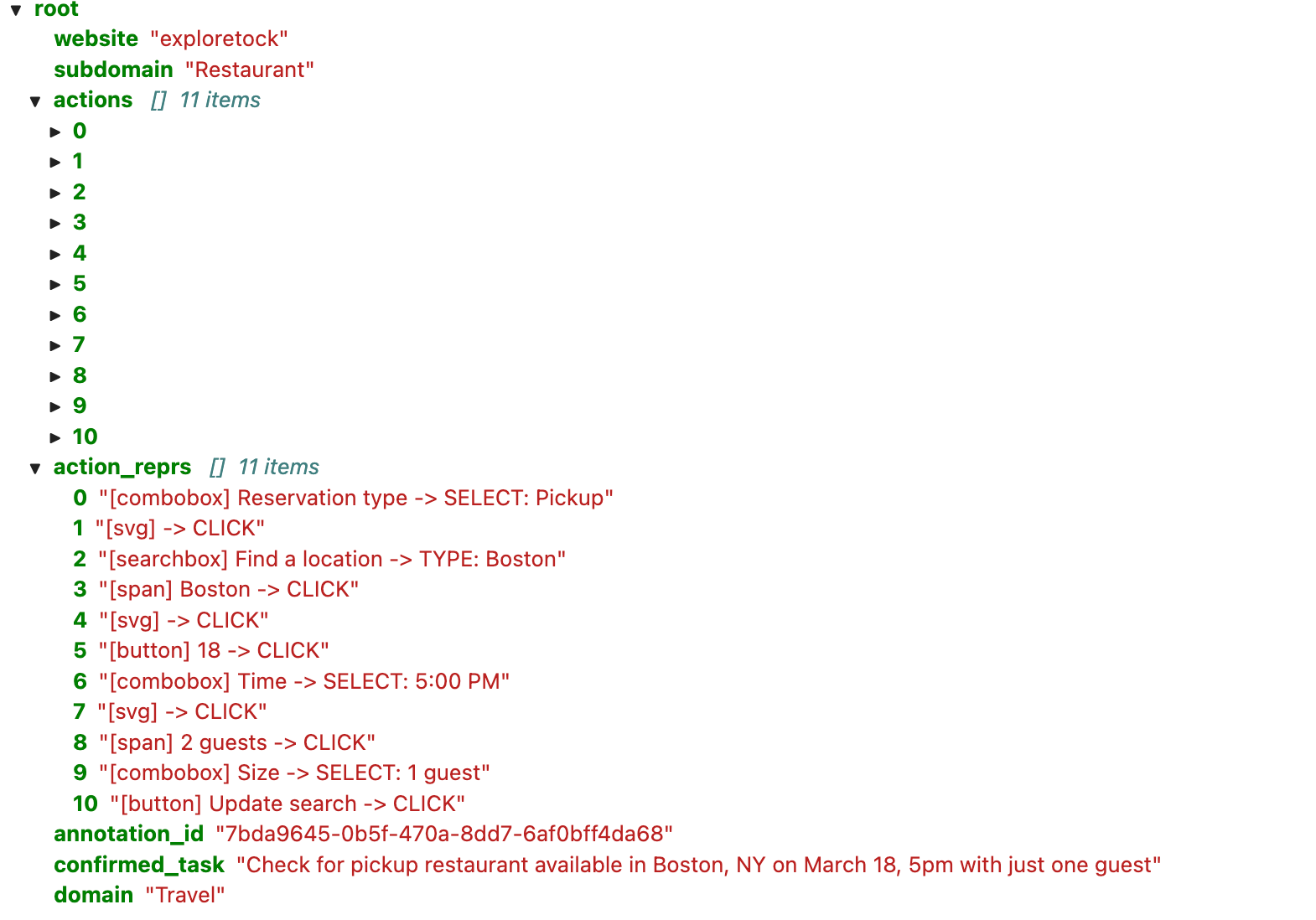
Focus on the MiniWoB++ environment, which is an RL-like little game environment but on web.
Strength
- novel(maybe? not sure) Recursively-Criticize and Improve prompt format
Challenges
- not that related so I didn’t read thoroughly.