Paper reading: WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
ZJU, Tencent, ACL2024
RQ: Previous study working on web understanding for LLM focus on managing complex HTML texts, while visual web agents have been overlooked.
Strengths
-
We introduce WebVoyager (Figure 1), a multimodal web agent designed to autonomously accomplish web tasks online from start to finish, managing the entire process end-to-end without any intermediate human intervention.
-
To accurately evaluate the capabilities of web agents in end-to-end task completion, we propose an automated evaluation protocol using GPT-4V. Specifically, we save screenshots throughout the online navigation process and then use GPT-4V to evaluate these trajectories together with the final results automatically.
-
Autogenerated dataset using self-instruct. Evaluate webvoyager on other datasets as well.
-
Use a visual mask (set-of-masking) to hint the clickable area
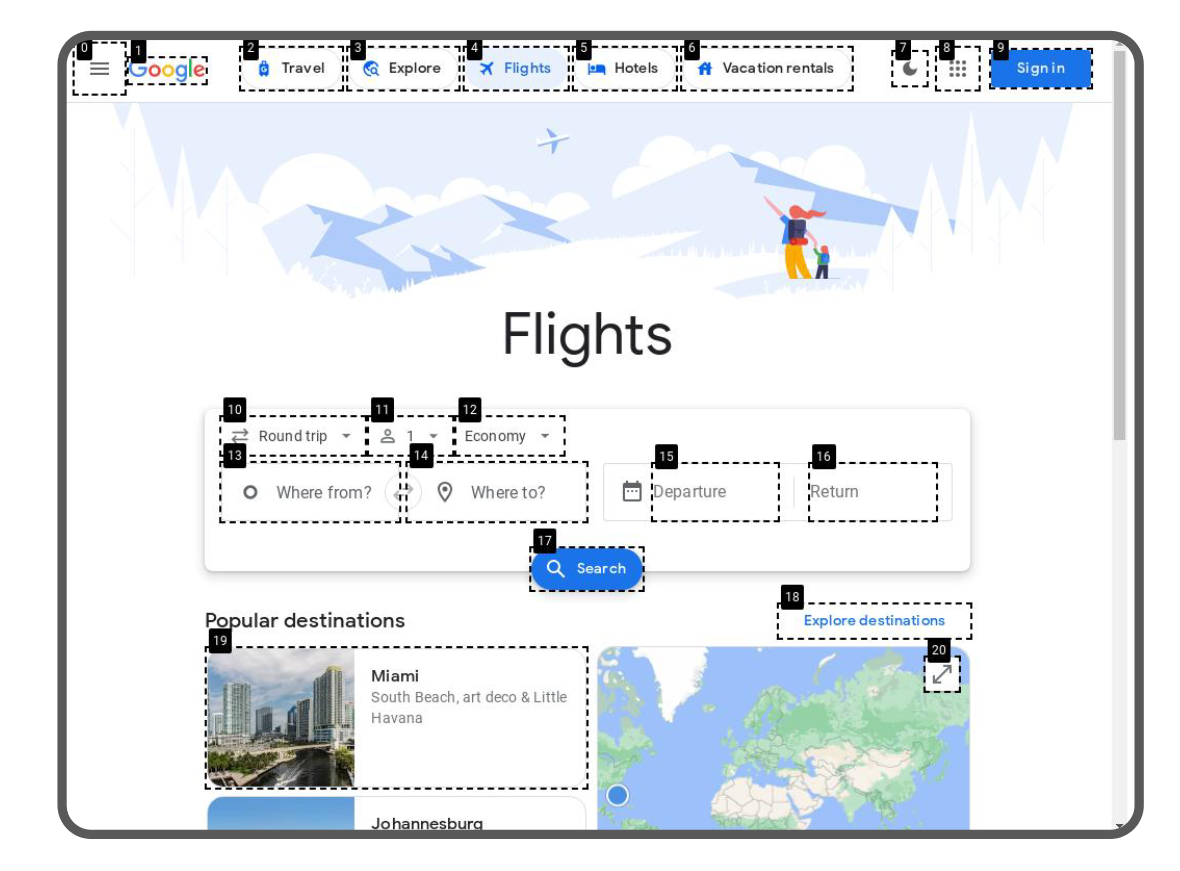
-
human evaluation of 300 tasks.
Drawbacks
- while I understand the difficulty in recruiting more participants for human evaluation, I’d like to see all models (not only gpt-4) to be evaluated by humans, as gpt-4 only show a ~60-70% success rate in human evaluation.
Dataset
1 | {"web_name": "Amazon", "id": "Amazon--0", "ques": "Search an Xbox Wireless controller with green color and rated above 4 stars.", "web": "https://www.amazon.com/"} |
40 amazon tasks in total, which is maybe useful?