Paper reading: Think before you speak: Training Language Models With Pause Tokens
First blog post in English! Today, let’s discuss: Think before you speak: Training Language Models With Pause.
Overall discussion
This paper was written by Sachin Goyal (a third-year PhD student from CMU) during his internship at Google Research. The basic idea of this paper is to inject <pause> tokens into the pre-training, fine-tuning, and inference stage of LLMs and see if it can improve performance on downstream tasks.
This idea is exactly what I proposed after I read the CoLT5 paper (I wrote part of it in this blog post in Chinese; I reported the whole idea in my group meeting): The computational power required by transformer models is only determined by their input sequence length. If we input n token into a transformer model, it takes O(n^2) computation steps and gives a prediction. Does this mean it can never “learn” how to tell if a number is a prime number, given that this task requires $O(\sqrt{2^n}) = O(2^{\frac{1}{2}n}) \gt O(n^2)$?
I suspected that the reason why Chain-of-Thoughts can improve performance is the context length is longer in my previous blog post, and I proposed that try adding dummy tokens to the context and see if there is any performance gain.
Introduction
The authors introduce the limitations of current model:
the number of operations determining the next token is limited by the number of tokens seen so far.
and the idea of “Pause-training”:
The approach we study is to append dummy tokens into a decoder-only model’s input, thereby delaying the model’s output.
and finally, the obvious question people may have on “pause-training” (which is also why this paper/experiment is important):
- the model may perform better because more computation is taken
- the model may perform worse because there is no additional information, no new parameters, and the new token may draw attention away.
The main contributions claimed by the author are:
-
pose the quesion:
what happens if we delay a model’s answer generation, and how can we execute these delays?
-
find that a performance improvement can be gained on a majority of downstream tasks through pause-pretraining, finetuning, and inference
-
introducing
<pause>token only in the finetuning stage doesn’t work -
some ablations
Method
Pause Pre-training
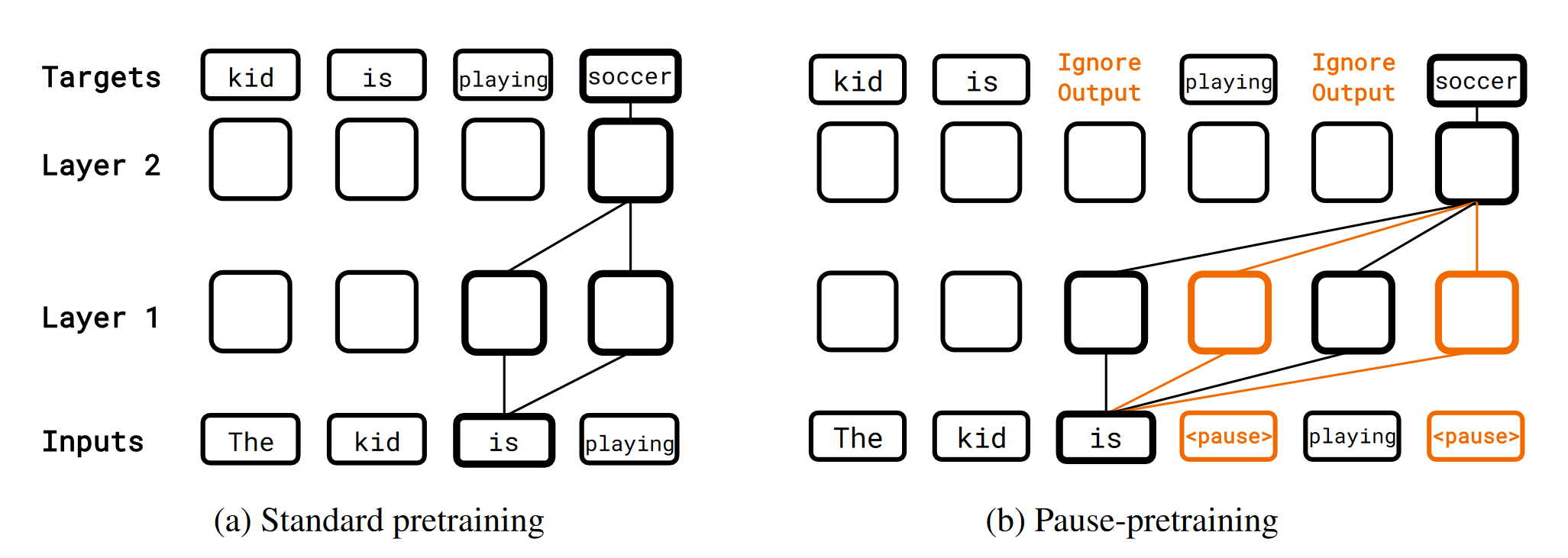
The method is quite straightforward. The authors insert b<pause> tokens at uniformly random locations to get a pause-injected sequence and then train the model on it, ignoring the loss on the <pause> token.
Pause Finetuning
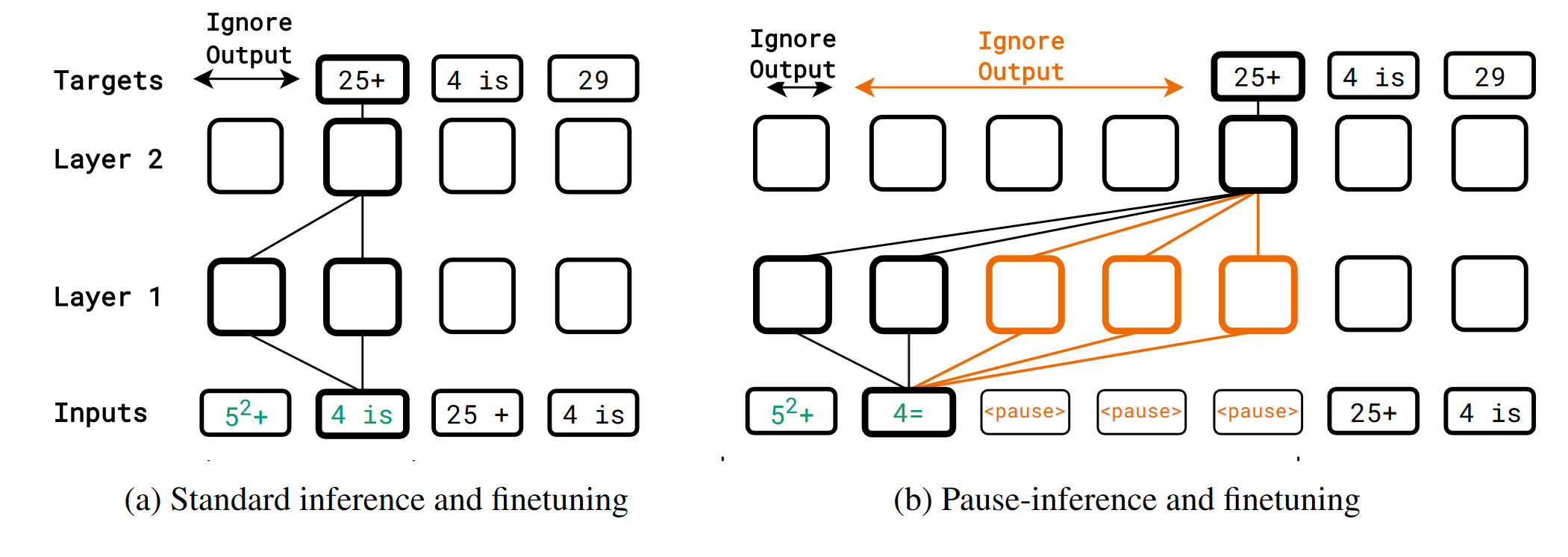
The authors define downstream tasks by a prefix $p_{1:N}$ and a target $t_{1:T}$, and append a certain number of <pause> token to $p_{1:N}$, then finetune the model with the loss on the target.
Experiment
The authors train 4 different models:
- Standard Pre-training and Standard Finetuning
- Standard Pretraining and Pause-Finetuning: to see if only adding
<pause>on finetuning works - Pause Pretraining and Standard Finetuning: to see if the performance gain is truly from the additional computation
- Pause Pretraining and Pause Finetuning
Result
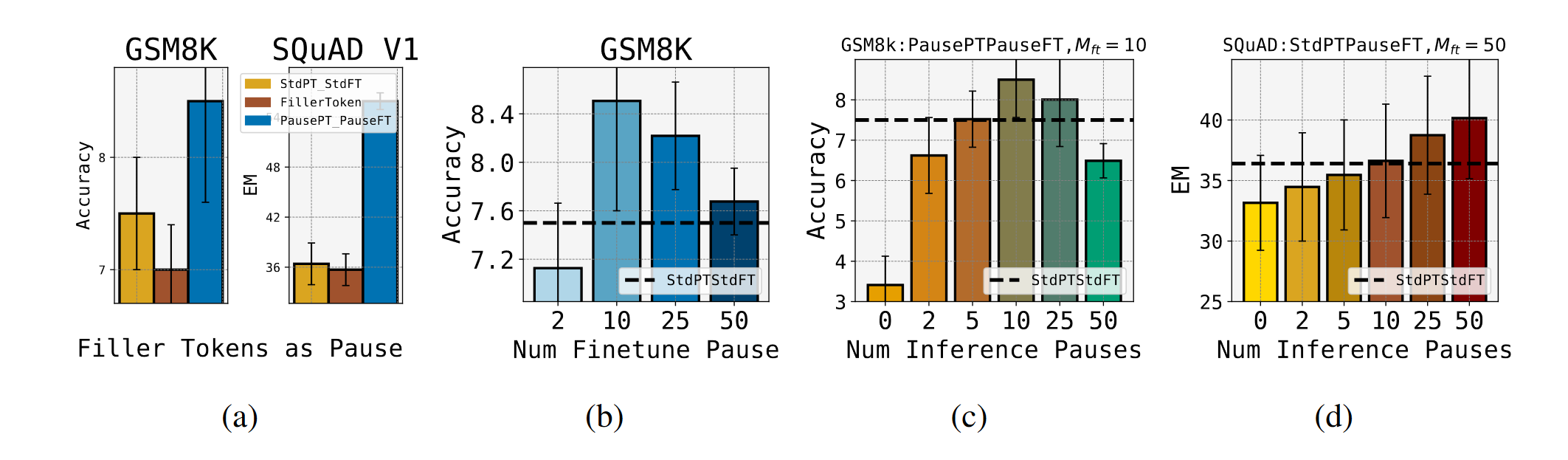
They found that using Pause Pretraining and Pause Finetuning results in much performance gain. And, interestingly, there are an optimal number of <pause> token for each task.
Conclusion
I’m happy to see my idea turn out to be effective! I didn’t have that computation power to evaluate it (in this paper, the author pre-trained at least 3 different 1B models on 200B tokens of data from scratch).
The authors also stated that because different tasks have an optimal number of pause tokens, some of them may be better at zero <pause>.