论文阅读: COLT5 + 运算优化真的只对长上下文有效吗?
论文阅读: COLT5: Faster Long-Range Transformers with Conditional Computation
这篇文章是google research的,主要聚焦在这个方法怎么来让Transformer-based LLM能支持更长的context length,并做了一个64k context lenght的LLM,达到了GPT-4的两倍。但是,我个人认为,这个方法的应用潜力不止于此,详见『总结』部分。
作者说,鉴于Transformer decoder的 $O(n^2)$ 量级的计算复杂度,对于超长context的处理一直是极为困难的。但是,尤其是对于长文本来讲,序列中并不是所有token都同样重要。所以,作者提出了COLT5这个方法,在FNN和attention部分进行选择性计算,把更多计算资源投入到更重要的token中。实验证明COLT5比LongT5用更少的计算量达到了更好的效果。作者还训练了一个64k context length 的LLM。
Introduction
处理长文本一直是自然语言处理任务的难题之一。过去的工作大多聚焦在减少attention部分的计算量。但是,对于大模型来说,大部分计算量是在FNN和投影部分。
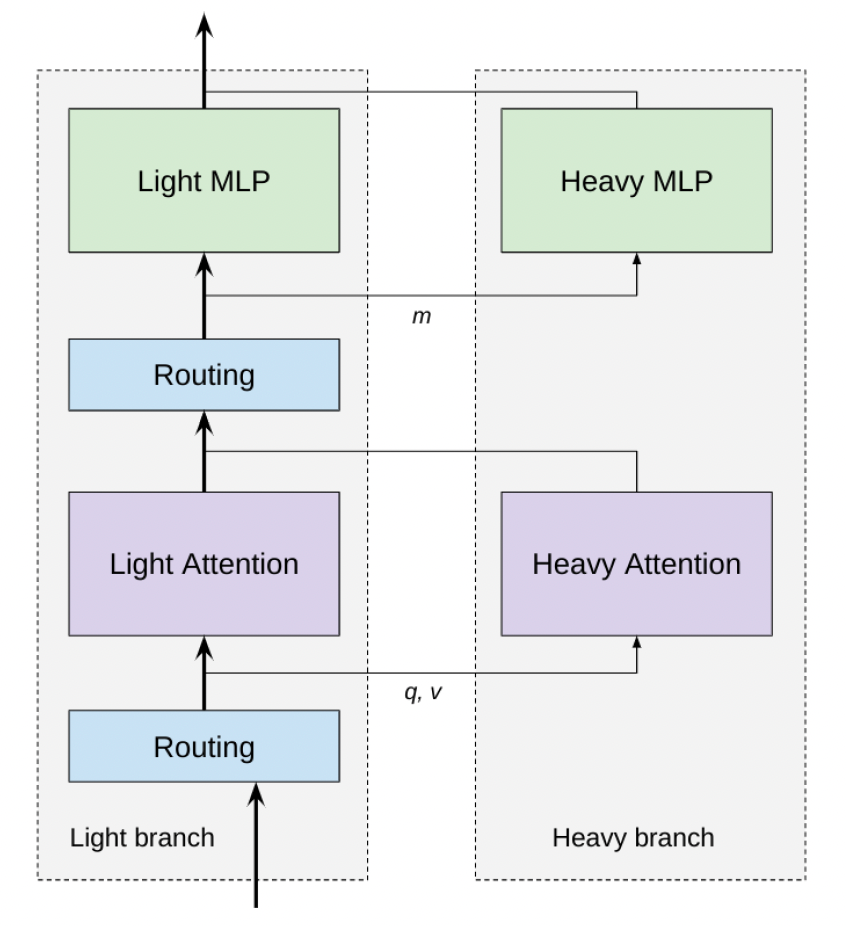
本文提出了一个条件性计算来减少计算量的方式:使用一个『light』的MLP(有更少的隐藏层)和一个『light』attention(有更少的attention head;只有local attention),并在需要的时候路由至『heavy』的MLP和attention来更好的分配资源。
方法
作者的观点认为,应该把有限的计算力分配给更重要的token。作者简单地把当前层的表示乘以一个投映矩阵后得到路由分数并选择一个固定比例 token来输入到heavy模块来减少计算量。特别的,作者对FNN、Attention Q和Attention K使用了3个不同的router。
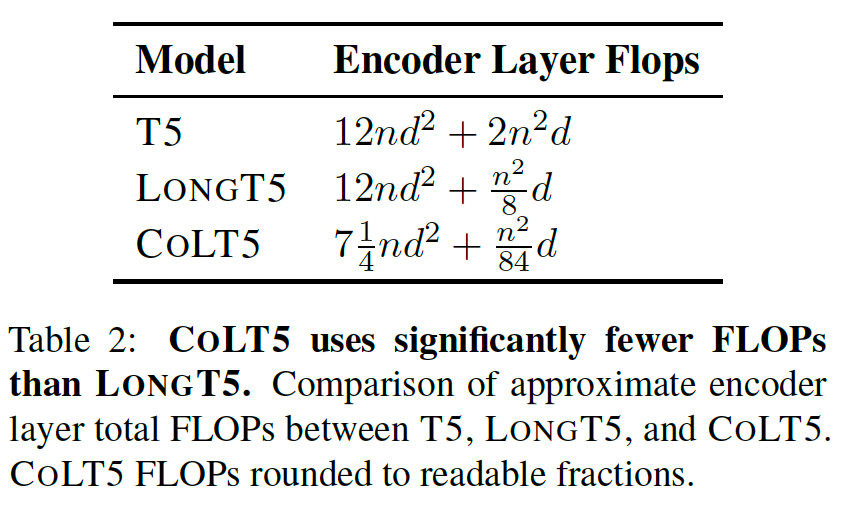
最终把flops的常数项(尤其是 $n^2$ 的常数项)优化了非常多。
总结
这篇文章提出了一个可以有效减少计算时间中 $n^2$ 常数项的方法,可以有效的帮助支持更长的context length。
但是,我想说的是另一个问题:在现有的transformer架构中,无论使用哪种模型(T5这样encoder和decoder都有的模型,还是GPT这样只有decoder的模型,抑或是COLT5这样选择性计算的模型),模型的计算量都是仅与输入+输出序列的长度有关的。但是,事实上真的是这样的吗?
仔细思考一下便会发现并不是。人在思考问题的时候,思考时间(可以近似为计算量)显然是和问题的复杂程度有关的。比如,加法的计算复杂度(以下的 $n$ 均指代输入序列长度,或者说信息量/bit)是 $O(n)$ ,乘法是 $O(n^2)$ ,而transformer的计算时间复杂度是 $O(n^2)$ ,那么我们是否可以认为transformer-based模型是可以完全『学会』加法和乘法的,即达到百分之百的正确率?而对于更复杂的问题,判断$n$是否为质数,这个时候的输入长度是 $\log n$ ,计算量却是 $\sqrt{n}$ ,而transformer的计算时间却是 $\log^2 n$ 量级的。我们是否可以认为transformer永远无法完全『学会』判断质数?(如果能的话,说明模型找到了一种新的判断质数的算法。)
计算量不够可能就是LLM无法完成『答案简短的数学运算』的原因之一(答案太短了导致计算量不够)。『Chain-of-thoughts』技术之所以有效,或许原因之一就是context长度显著变长之后计算量更大了?
这里拿数学计算任务举例,但是同样的结论显然也可以应用更复杂的如QA等任务上。LLM使用『大力出奇迹』的方式,用固定的、极大的计算量期望解决大部分问题。但是,这样不仅浪费了算力,同时也会导致LLM会对于大计算量需求的任务给出一个似是而非的答案,同时从根本上永远无法给出正确答案。如果LLM可以自主决策『对于这个任务我要使用更多算力』,可能可以更好的解决任务,同时对于简单任务使用更少的资源。