PowerPC is IBM’s architecture and nobody but IBM is using it anymore. IBM have their own build of PyTorch and TensorFlow to powerpc, which called the powerai bundle, however the last update was 4 years ago and it only supports pytorch 1.3.
So I HAVE to build PyTorch myself. Building softwares is fairly easy on Linux, as long as you know to put the right thing in the right place.
I choose 1.12.1 because it seems that it’s the last version that supports cuda 11.2. With some modification to the code, pytorch 2.0.1 seems to compile but eventually fail with an error that I don’t have time to figure out how to solve.
These steps is used inside a cluster that I don’t have sudo access. Running cuda installer will result in segmentation fault but luckily the system admin have cuda 11.2 installed at /usr/local/cuda. The system don’t have CUDNN though, however it is possible to use CUDNN from conda-forge.
install miniforge
create a new mamba environment, with mamba create -n <your_env_name_here> python=3.10 cudatoolkit=11.2 cudnn libopenblas blas cmake ninja
clone PyTorch; git checkout v1.12.1; IGNORE pytorch document that asks you to install mkl.
1 2 3
cd pytorch git submodule sync git submodule update --init --recursive
export MAX_JOBS=40 # limits the total number of threads. # Each PPC core have 4 hardware threads but will cause too much stress to the file system, so I'm running one thread per core. python setup.py build
First blog post in English! Today, let’s discuss: Think before you speak: Training Language Models With Pause.
Overall discussion
This paper was written by Sachin Goyal (a third-year PhD student from CMU) during his internship at Google Research. The basic idea of this paper is to inject <pause> tokens into the pre-training, fine-tuning, and inference stage of LLMs and see if it can improve performance on downstream tasks.
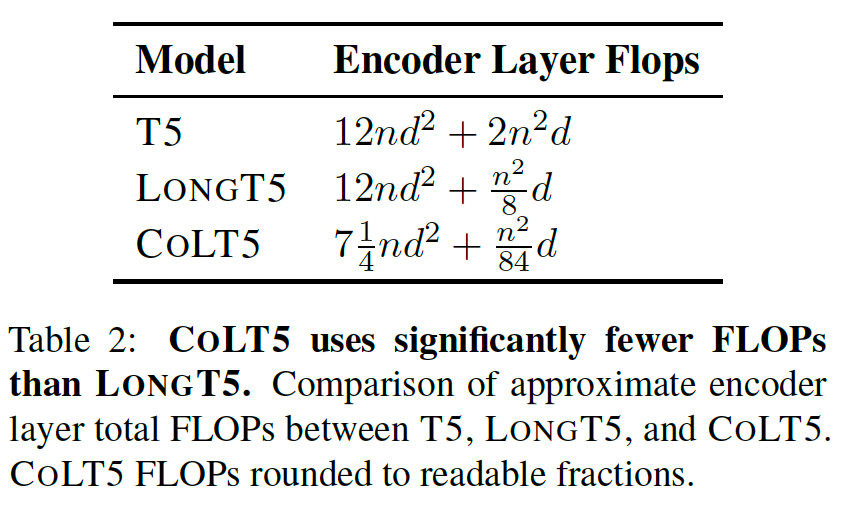
This idea is exactly what I proposed after I read the CoLT5 paper (I wrote part of it in this blog post in Chinese; I reported the whole idea in my group meeting): The computational power required by transformer models is only determined by their input sequence length. If we input n token into a transformer model, it takes O(n^2) computation steps and gives a prediction. Does this mean it can never “learn” how to tell if a number is a prime number, given that this task requires $O(\sqrt{2^n}) = O(2^{\frac{1}{2}n}) \gt O(n^2)$?
I suspected that the reason why Chain-of-Thoughts can improve performance is the context length is longer in my previous blog post, and I proposed that try adding dummy tokens to the context and see if there is any performance gain.
Introduction
The authors introduce the limitations of current model:
the number of operations determining the next token is limited by the number of tokens seen so far.
and the idea of “Pause-training”:
The approach we study is to append dummy tokens into a decoder-only model’s input, thereby delaying the model’s output.
and finally, the obvious question people may have on “pause-training” (which is also why this paper/experiment is important):
the model may perform better because more computation is taken
the model may perform worse because there is no additional information, no new parameters, and the new token may draw attention away.
The main contributions claimed by the author are:
pose the quesion:
what happens if we delay a model’s answer generation, and how can we execute these delays?
find that a performance improvement can be gained on a majority of downstream tasks through pause-pretraining, finetuning, and inference
introducing <pause> token only in the finetuning stage doesn’t work
some ablations
Method
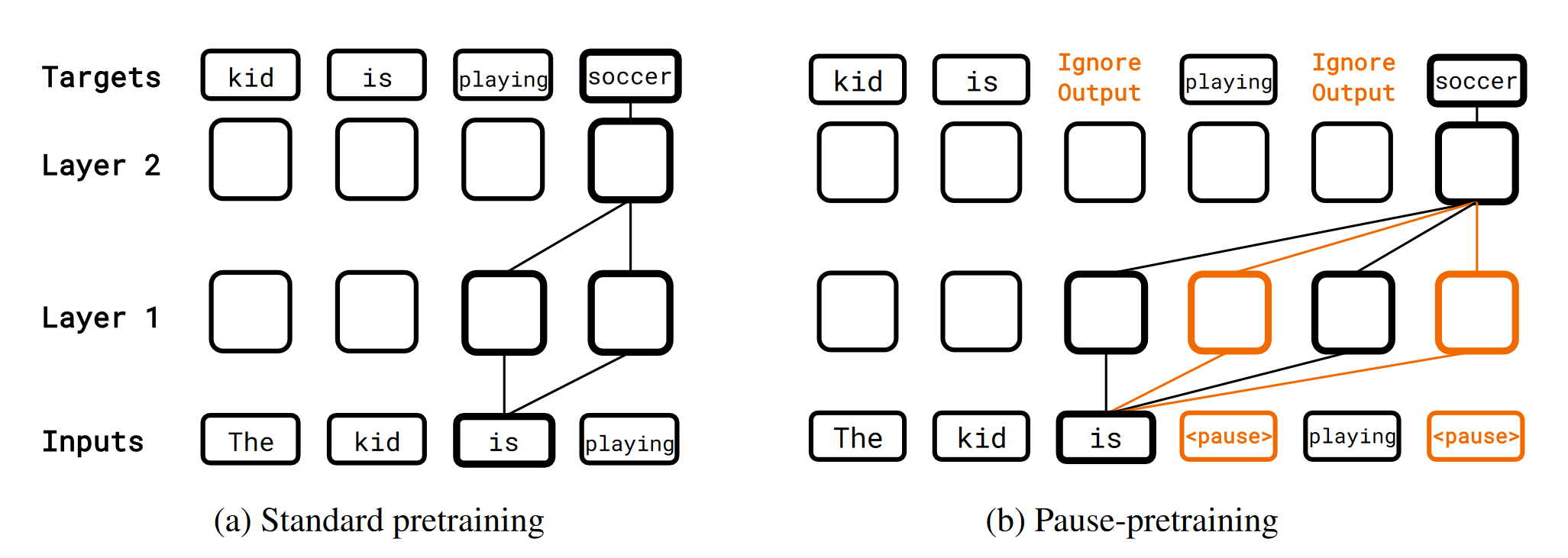
Pause Pre-training
The method is quite straightforward. The authors insert b<pause> tokens at uniformly random locations to get a pause-injected sequence and then train the model on it, ignoring the loss on the <pause> token.
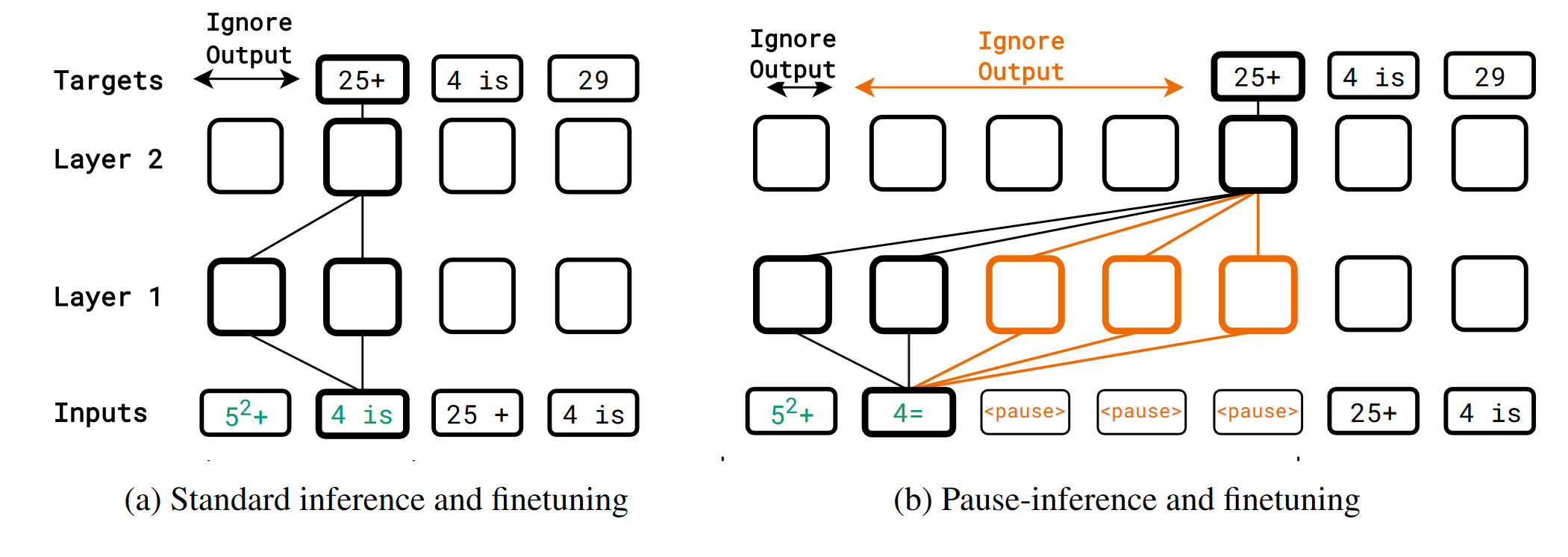
Pause Finetuning
The authors define downstream tasks by a prefix $p_{1:N}$ and a target $t_{1:T}$, and append a certain number of <pause> token to $p_{1:N}$, then finetune the model with the loss on the target.
Experiment
The authors train 4 different models:
Standard Pre-training and Standard Finetuning
Standard Pretraining and Pause-Finetuning: to see if only adding <pause> on finetuning works
Pause Pretraining and Standard Finetuning: to see if the performance gain is truly from the additional computation
Pause Pretraining and Pause Finetuning
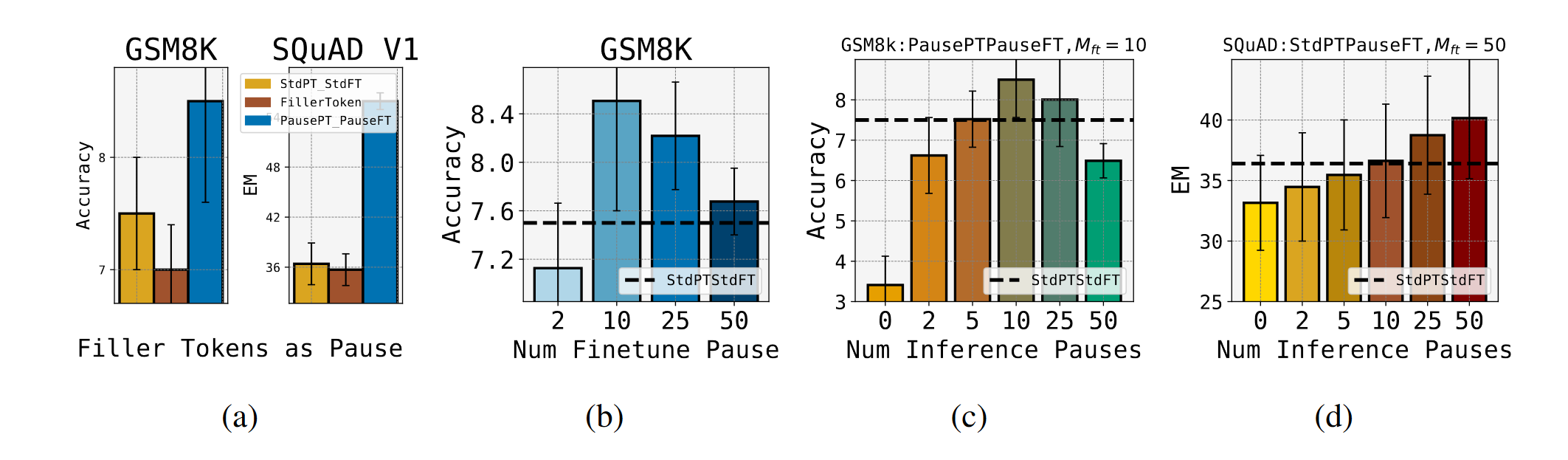
Result
They found that using Pause Pretraining and Pause Finetuning results in much performance gain. And, interestingly, there are an optimal number of <pause> token for each task.
Conclusion
I’m happy to see my idea turn out to be effective! I didn’t have that computation power to evaluate it (in this paper, the author pre-trained at least 3 different 1B models on 200B tokens of data from scratch).
The authors also stated that because different tasks have an optimal number of pause tokens, some of them may be better at zero <pause>.
I’ve always been curious about the internal implementations of operating systems. I recently deployed kanidm in my home lab, and I’ve leaned a lot about how does linux authentication works during this process. These paragraph is licensed under CC-BY-NC-SA 4.0. I’m writing this post to share my thoughts and share my translation of this fantastic blog from Firstyear in Chinese.
The Unix access rights flags setuid and setgid (short for set user identity and set group identity) allow users to run an executable with the file system permissions of the executable’s owner or group respectively and to change behaviour in directories.
While I was learning Operating Systems at my school, it suddenly occurred to me that I don’t know how sudo works. Based on my little knowledge of Linux, I made the following assumption:
There should be a syscall for elevating privileges
sudo collects user’s password, and pass it to the syscall
However, almost immediately, I found some problems of my assumption:
sudo asks for the password of the current user, not the root user; and who is allowed to sudo is stored in sudoers
So the syscall for elevating privileges should be able to know who can do that
But it is unlikely that the syscall reads the sudoers file
sudo supports controlling which command a user is allowed to run
This is too complicated to be integrated into the kernel.
After some digging, I found the syscall setuid. It is able to set the uid of the current process. After some further searching, I found that this syscall is only for lowering the permissions: You have to have CAP_SETUID to run it. Then, in a scenario like sudo, when does the permission “elevation” happens?
After some trial, I discovered that when sudo is asking for password, the uid of it’s process is already 0, which means that the binary file sudo have something unique which makes it can directly be run as root. At this point, the answer is quite obvious: the only reasonable answer is that the permission is stored in the file system. Again, after some searching, I found that the file system maintains some special permission other than regular rwx. sudo uses setuid:
The Unix access rights flags setuid and setgid (short for set user identity and set group identity) allow users to run an executable with the file system permissions of the executable’s owner or group respectively and to change behaviour in directories.
So, the permission is temporarily elevated to root (who is the owner of sudo). sudo itself can determin whether the user is able to maintain the root permission or switch to other users. That is also why sudo breaks if you run chmod -R 755 /usr/bin.
This my first understanding of linux authentication system.