Paper reading: SteP: Stacked LLM Policies for Web Actions
SteP: Stacked LLM Policies for Web Actions
Cornell and ASAPP research; CoLM 2024
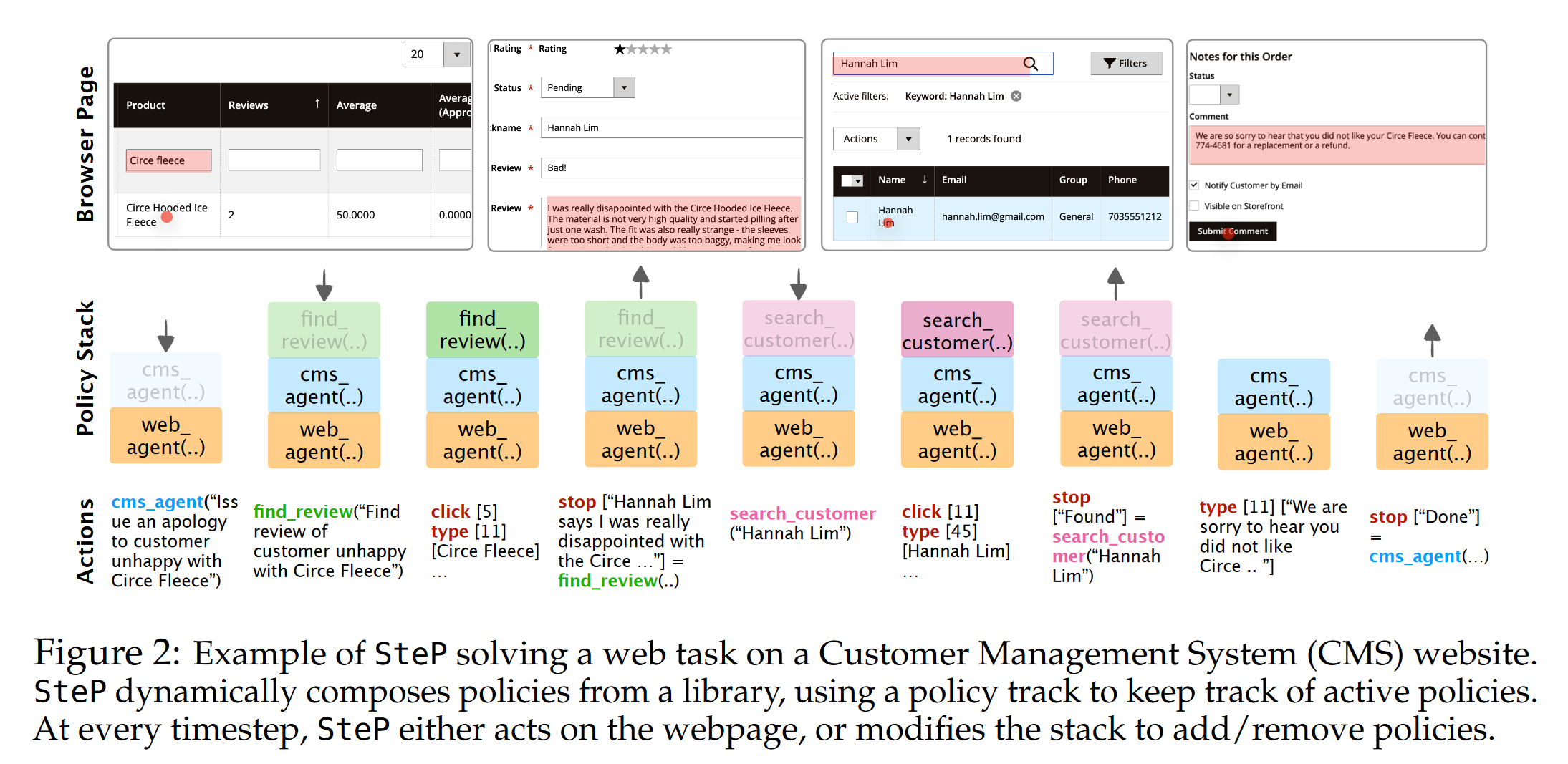
Author’s claim: Specifying a large prompt to handle all possible behaviors and states is extremely complex; decomposition to distinct policies requires careful handling of control between policies. They propose Step, an approach to dynamically compose policies to solve a diverse set of web tasks.
Use Markov Decision Tree where the state is a stack of policies.
Enable dynamic control where any policy can choose to invoke any other policy
Strengths
- some sort of “mid-level intent” prompt for completing high-level tasks
Challenges
- I didn’t realize how policies are constructed when reading the introduction and the abstract.
- Okay, I see why they are trying to avoid saying that. policies are manually crafted.
- Then the need for manual crafting policies is a big issue.