论文阅读: Self-Instruct: Aligning Language Model with Self Generated Instructions
一直觉得应该找一个形式把读过的论文以除了组会分享报告之外的形式记录下来。最近看到同学的论文阅读分享,终于决定也开始写blog。
今天看的这篇是 Self-Instruct , 是最近很火的 instruct tuning(给LLM增加 follow instruct 的能力)方法。之前InstructGPT等方法都是需要人工标注的instruct数据(在SFT阶段),这篇工作提出,既然LLM的能力已经足够强,只需要构造Prompt,从LLM中挖掘instruct信息,从而来tune自己。
本质上,作者证明了『可以从 few-shot 能力很强的LLM来bootstrap出一套 SFT 数据集,从而得到 zero-shot 或者说 Instruct-tuned LLM』。
作者来自华盛顿大学,感觉是要投今年的ACL。他们声称用GPT3达到了类似 text-davinci-001 (仅SFT的InstructGPT)的效果,比用 SuperNaturalInstructions 数据集训练的效果类似。这篇文章发布于22年12月,当时chatgpt刚发布不久,所以只对比了 InstructGPT?(好像跟ChatGPT也没法比)。
Stanford 也用这个方法,用 text davinci 003 造了个数据集后基于 LLaMa 训练了 Alpaca 模型,在7B这样一个参数量下达到了相当惊艳的效果。这也是证明 instruct tuning 不需要花很多钱就能做到的一个证据?Alpaca开源了他们生成的52k个instruction,这可能是 llm 的 stable diffusion moment 的开端?
Introduction
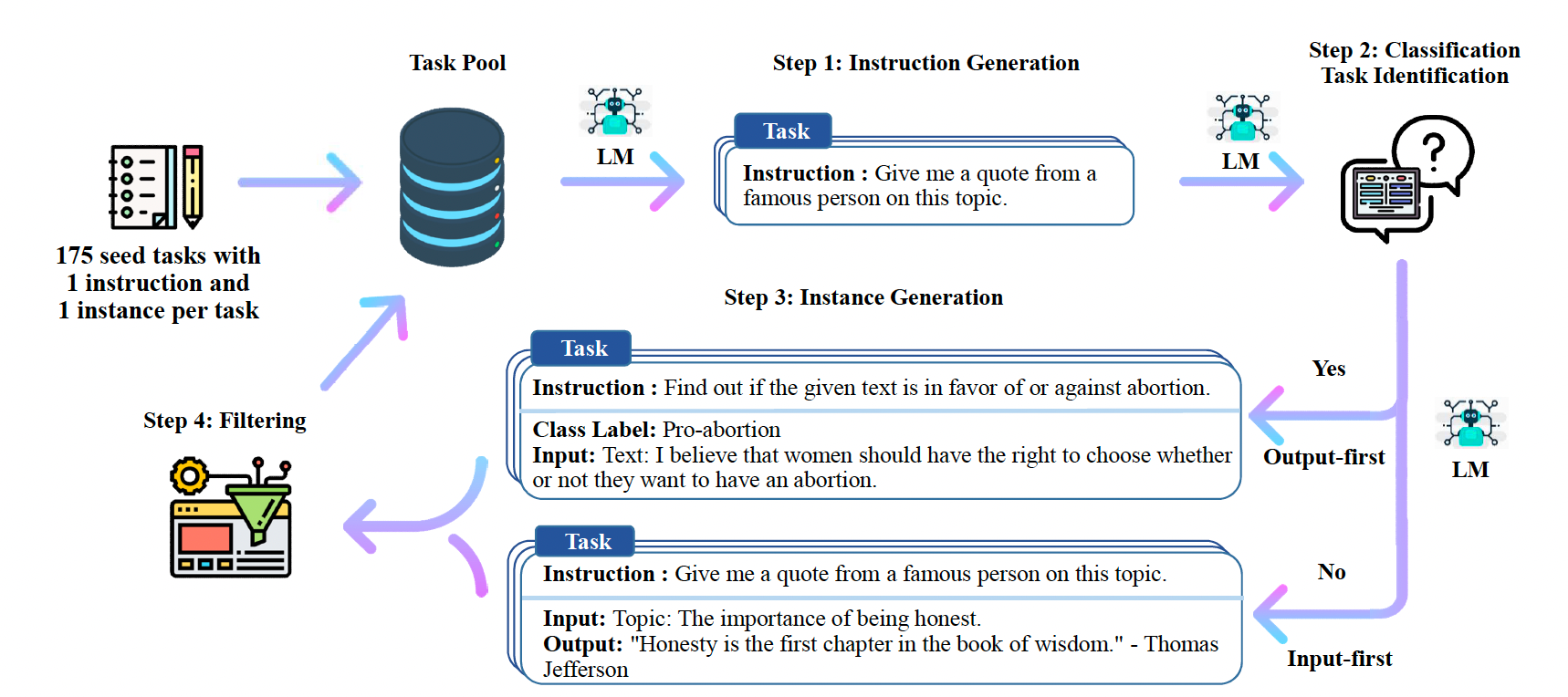
作者先讲了最近大家都在做 instruction tuning 的工作,说现在的方法都需要人工构建instruct数据集。于是,他们提出self-instruct方法,视图让LLM自我构建一个 instruct 的数据集,来做到自己训练自己:从一个很短的(175个)人手写的数据集来bootstrap,主要有一下步骤:
- 要求模型生成新任务的instruction
- 利用现有的任务描述,让模型生成新的任务和新的指令。通常,模型会定义一些新的任务出来
- 生成 input-output pair
- 过滤掉重复的和低质量的pair
- 然后把他们添加到 task pool 中
总结一下贡献:
- 提出 self-instruct 方法
- 跑了很多实验来证实有效性
- 开放了52k个instructions
- (alpaca 开放了用同样方法构建的、基于text-davinci-003的数据)
Method
Instruction Generation
第一步是生成一些新的task和instruction。他们使用以下的prompt来生成:
1 | Come up with a series of tasks: |
简单来讲就是让模型进行 in-context learning. 用175个人写的instruction来初始化 task pool,之后每次随机选6个人写的和2个机器生成的task来生成新的task。
Classification Task Identification
因为后续的步骤对于 Classification 任务和其他任务的处理方法不同(在这里,他们把 有有限的、小的输出label集合的任务定义为分类任务),他们用了原版GPT3的few shot learning 来做这个分类,用了12个分类任务的instruction和19个非分类任务的instruction作为prompt。
Instance Generation
第三步是用task来生成一些任务的 input-output pair。作者认为,传统的方法先生成input再生成output,在分类任务上会有类别不平衡的问题。所以,对于分类任务,他们用了 output-first 的方法:先生成可能的label,再根据这些label生成可能的输入。
Filtering and Post-processing
为了保证instruct的多样性,他们仅当新的instruction和旧的的 rouge-l 分数小于 0.7 时才会把它加入到 task pool 中。同时,他们排除了常见的llm无法解决的问题的关键词(image等)。最后,在生成 instance 的时候,他们去掉了完全相同的或者有相同input的。
Finetuning the LM
最后一步是用这些数据来finetune LM。 为了保证鲁棒性,他们混和多种prompt(如是否添加 Task: 等)。
实验结果
作者先在 super-naturalinstructions 数据集上跑了和 t0、gpt3的对比试验,发现加上self-instruct后效果先祖很好、能和instructGPT接近。
同时,在一套新的instruct set 上进行了人工评分:
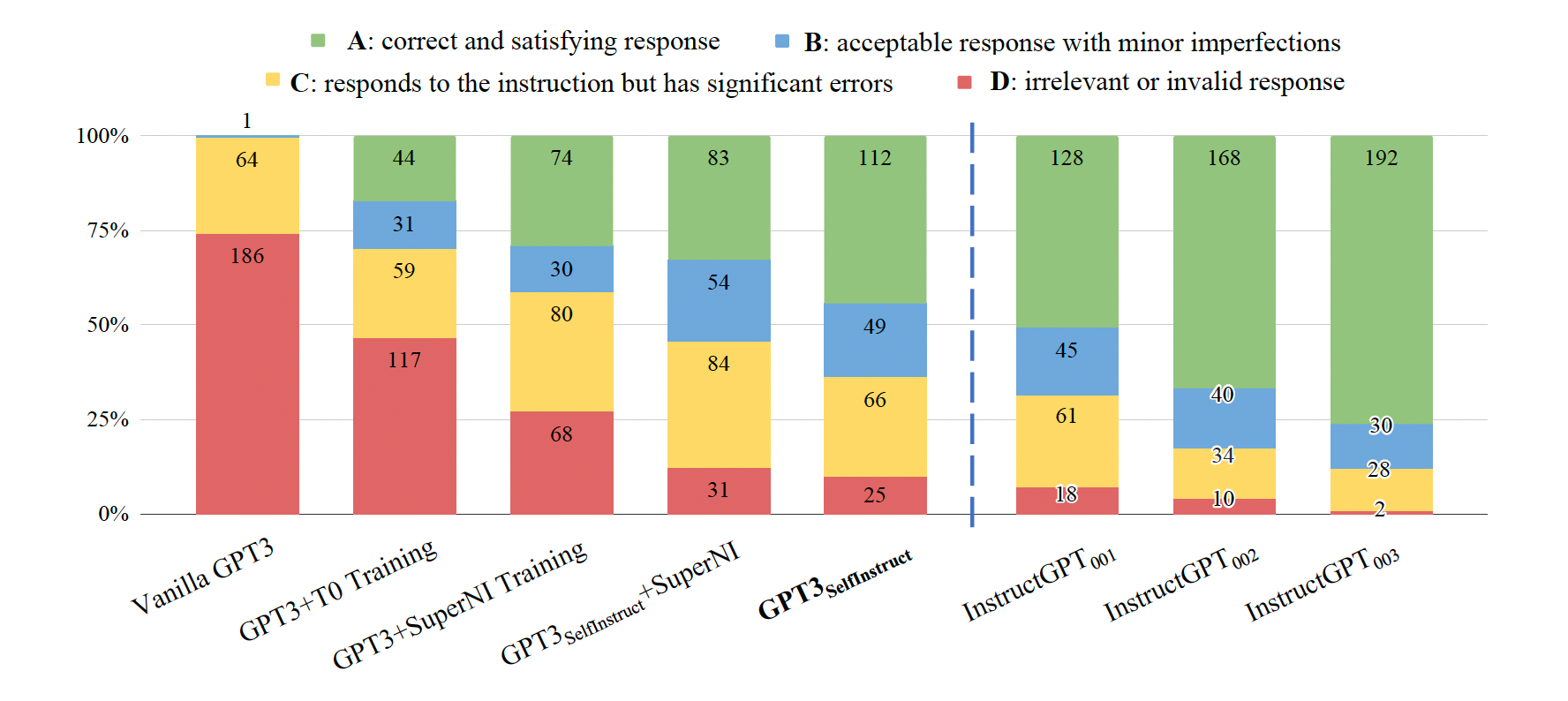
效果和 InstructGPT_001 类似。
结论
作者证明了可以用 LLM 来生成自己的训练数据,也就是说,只需要花几百刀(作者说用了$338左右)来调用OpenAI的API就可以复现一个InstructGPT。同时,后续stanford释出的数据集和alpaca模型也都证明了这个方法的有效性。
作者自己说,缺点包括会强化LLM的bias(如性别、种族等)。我感觉,是否能改善LLM的safeness也许要更多试验。